
Ilya Kavalerov

PhD
Electrical
Engineering
Ilya received the Ph.D. degree in Electrical Engineering at the University of Maryland, College Park. His thesis was titled "Impact Of Semantics, Physics, And Adversarial Mechanisms In Deep Learning". He was a research intern at Google Cambridge in 2018, and Google Mountain View in 2019. His research interests include scattering transforms, deep learning, generative adversarial networks, and computer vision. Previously, Ilya worked atArtsy, the Pandora of the Art-world, working on their API, systems availability, and predictive models. He received the B.Sc. degree in Chemistry and B.A. degree in English at the George Washington University in Washington D.C. in 2013. Hisundergraduate thesis examined the neuroscience of narrative.
cGANs with
Multi-Hinge Loss- Read the Paper on Arxiv
- Use the code

WACV 2021
We propose a new algorithm to incorporate class conditional information into the critic of GANs via a multi-class generalization of the commonly used Hinge loss that is compatible with both supervised and semi-supervised settings. We study the compromise between training a state of the art generator and an accurate classifier simultaneously, and propose a way to use our algorithm to measure the degree to which a generator and critic are class conditional. We show the trade-off between a generator-critic pair respecting class conditioning inputs and generating the highest quality images. With our multi-hinge loss modification we are able to improve Inception Scores and Frechet Inception Distance on the Imagenet dataset.
A study of quality
and diversity
in K+1 GANs- Paper website

ICBINB NeurIPS Workshop 2020
We study the K+1 GAN paradigm which generalizes the canonical true/fake GAN by training a generator with a K+1-ary classifier instead of a binary discriminator. We show how the standard formulation of the K+1 GAN does not take advantage of class information fully and show how its learned generative data distribution is no different than the distribution that a traditional binary GAN learns. We then investigate another GAN loss function that dynamically labels its data during training, and show how this leads to learning a generative distribution that emphasizes the target distribution modes. We investigate to what degree our theoretical expectations of these GAN training strategies have impact on the quality and diversity of learned generators on real-world data.
3-D Fourier
Scattering for
HSI images- Read the Paper
- Read the Paper on Arxiv
- Use the code

IEEE Transactions on Geoscience and Remote Sensing 2020
Recent developments in machine learning and signal processing have resulted in many new techniques that are able to effectively capture the intrinsic yet complex properties of hyperspectral imagery. Tasks ranging from anomaly detection to classification can now be solved by taking advantage of very efficient algorithms which have their roots in representation theory and in computational approximation. Time-frequency methods are one example of such techniques. They provide means to analyze and extract the spectral content from data. On the other hand, hierarchical methods such as neural networks incorporate spatial information across scales and model multiple levels of dependencies between spectral features. Both of these approaches have recently been proven to provide significant advances in the spectral-spatial classification of hyperspectral imagery. The 3D Fourier scattering transform, which is introduced in this paper, is an amalgamation of time-frequency representations with neural network architectures. It leverages the benefits provided by the Short-Time Fourier Transform with the numerical efficiency of deep learning network structures. We test the proposed method on several standard hyperspectral datasets, and we present results that indicate that the 3D Fourier scattering transform is highly effective at representing spectral content when compared with other state-of-the-art spectral-spatial classification methods.
Universal Sound
Separation- Read the Paper
- Read the Paper on Arxiv
- Use the dataset
- Paper website
WASPAA 2019
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown how performance on speech tasks carries over to non-speech tasks. To study this question, we develop a dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore both a short-time Fourier transform (STFT) and a learnable basis, as used in ConvTasNet. For both of these bases, we also examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.
Technologies:
Harmonic Analysis.
Description:
In Harmonic Analysis and other fields we are interested in breaking a signal into pieces. To generalize the Fourier decomposition, and measure physical quantities other than the frequency content of a signal, we may decompose a signal into the spectrum of a general self adjoint operator. It is interesting to study the relationship between the spread in energy in the original domain and the new domain defined by the operator. This paper explores a generalization of the celebrated Heisenberg Uncertainty Principle from Quantum Mechanics.
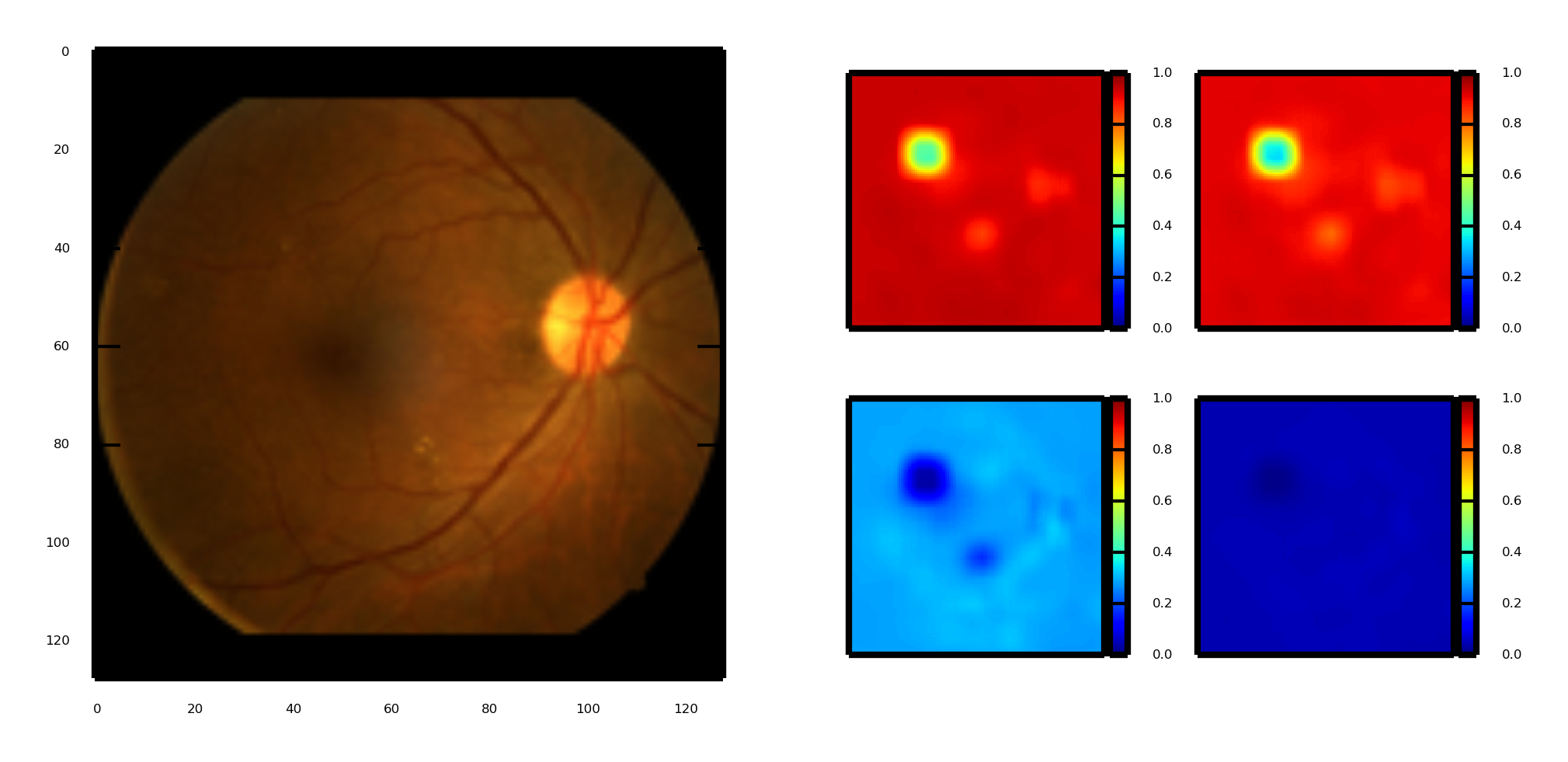
Technologies:
Theano, OpenCV, Python, Deep Learning.
Description:
A 3rd percentile solution (20th out of 616 place) for the Kaggle Diabetic Retinopathy (DR) Challenge, see me on theleaderboard here. A ConvNet that classifies the severity of DR in an image of an eye fundus (0-4 scale). A writeup explaining the research and code is availableonline. The image of heatmaps shows the probability of each of 1 of 4 pathological classes being output if that pixel was occluded. Here the ConvNet learned the 2-3 pixel pattern in a 128px image for a hard exudate (click on the image to zoom in).

Technologies:
OpenCV, Python, Linear Algebra.
Description:
An unsupervised algorithm that detects the edges of artworks in images, and rotates/crops the images to eliminate the background. A writeup explaining the theory and code is availableonline. (Images are from theGetty Open Content Program)
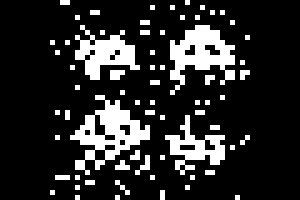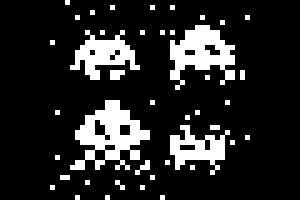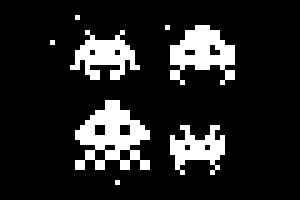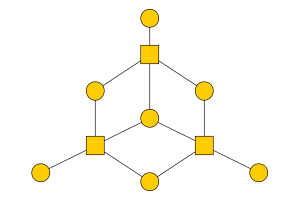
Technologies:
Python, Graphical Models, Belief Propagation.
Description:
A python library that implements Belief Propagation for factor graphs, also known as the sum-product algorithm. Used for inference on graphical models, ex: decoding error correcting codes like LDPC codes (in the gif).(Image of the (7,4) Hamming code created with yEd)
Technologies:
Ruby on Rails, Combinatorics (Block Design with Monte Carlo methods).
Description:
A web app for facilitating S'Ups (short for 'standups,' i.e. quick meetings) between the employees of a company. Each week three members are grouped into diverse arrangements where 1) no member can have any work-team memberships in common and 2) members have not been grouped with either of the other members recently.
Technologies:
Ruby on Rails, Backbone.js, HTML5, CSS, Sass, Adobe Photoshop, Illustrator. Used MapBox.js, Leaflet.js, Google Places, and MapQuest Geocoding APIs and Libraries.
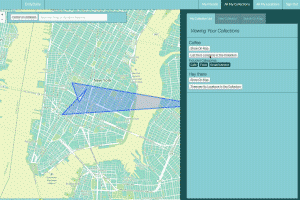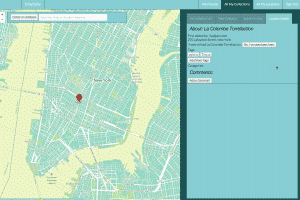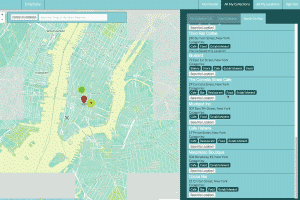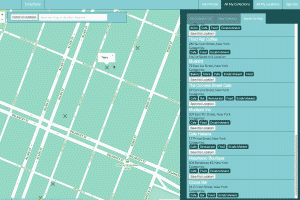
Description:
Location and itinerary saving and sharing single page app.
Technologies:
JavaScript, AJAX, jQuery, HTML5 Canvas.
Description:
Take a break from cruising the net and play the classic Snake and Asteroids games on my website.